ICML, 2026
DyLLM
Original code is available here.
Diffusion LLMs (dLLMs) are a promising alternative to autoregressive LLMs. Unlike autoregressive decoding, diffusion LLMs inherently support parallel decoding with a controllable parallel degree. However, diffusion LLMs use bidirectional attention, which requires full-token computation at every denoising step. As a result, each step can be as compute-intensive as the prefill stage in autoregressive LLM inference, reducing the practical benefit of parallel decoding.
DyLLM is motivated by the observation that only a small subset of tokens changes significantly between adjacent denoising steps. DyLLM identifies these tokens as salient tokens by measuring the cosine similarity between the current attention output vector and the cached attention output vector from the previous step. If a token vector changes beyond a given threshold, it is selected as salient and passed through the FFN. For non-salient tokens, DyLLM safely reuses the FFN output from the previous step.
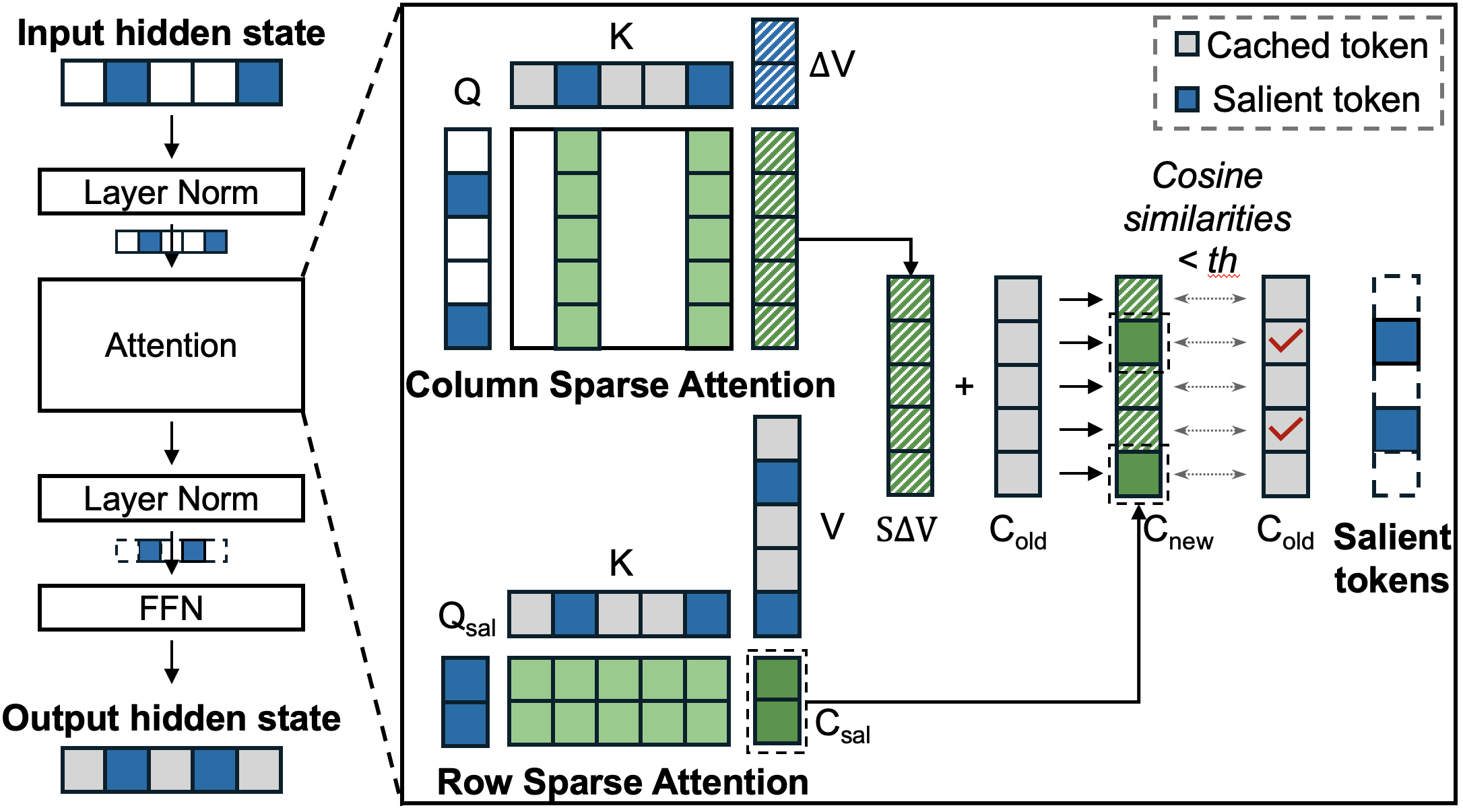
DyLLM also reduces the cost of attention. Instead of computing exact attention for all tokens, it computes exact attention only for salient tokens. For non-salient tokens, DyLLM approximates the attention-context update using the changes induced by salient tokens and updates the context cache accordingly.
Implementation
DyLLM is implemented in PyTorch. For sparse operations such as sparse attention and cache updates, we implement custom CUDA kernels to reduce the overhead of native PyTorch operations. Since cosine similarity computation is memory-intensive, we fuse it with the sparse attention operation to improve memory efficiency.
Evaluation
DyLLM accelerates diffusion LLM inference by an order of magnitude without substantial accuracy loss.
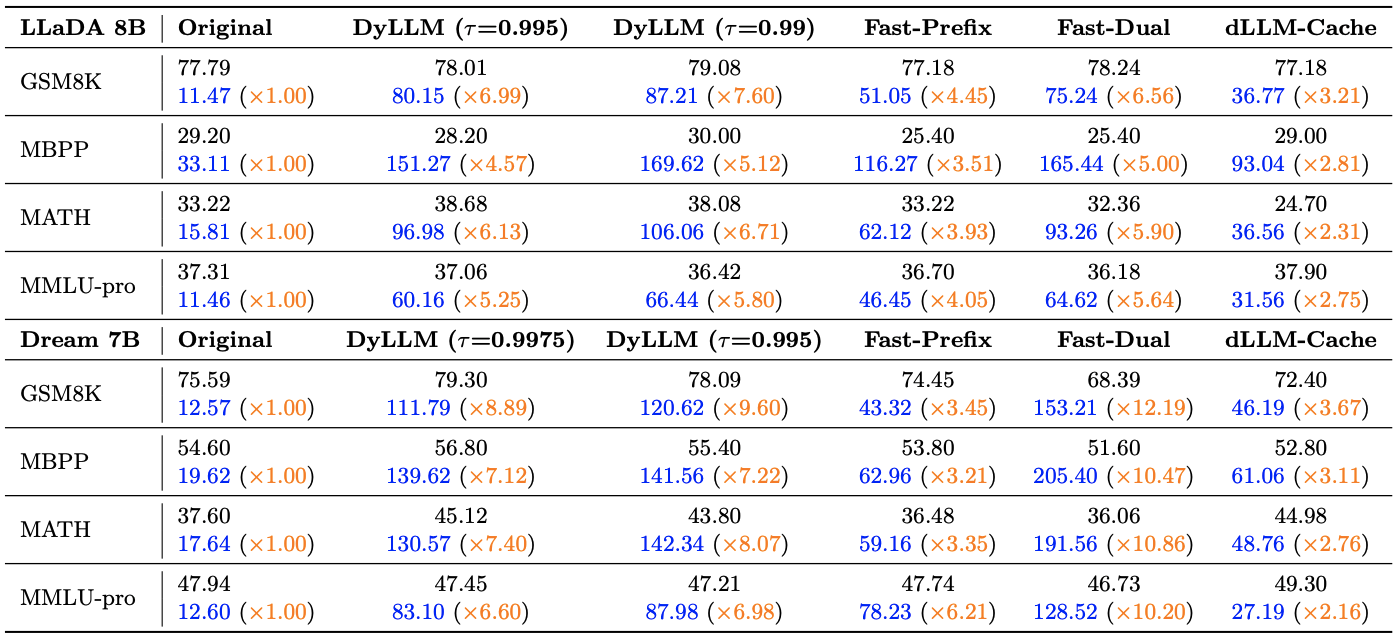
For more details, please see our paper.